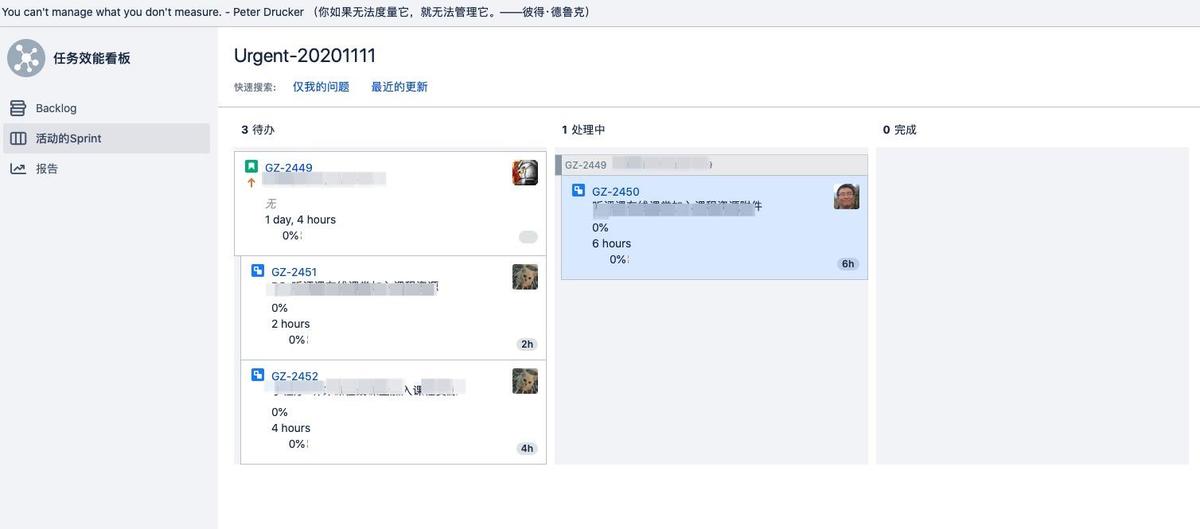
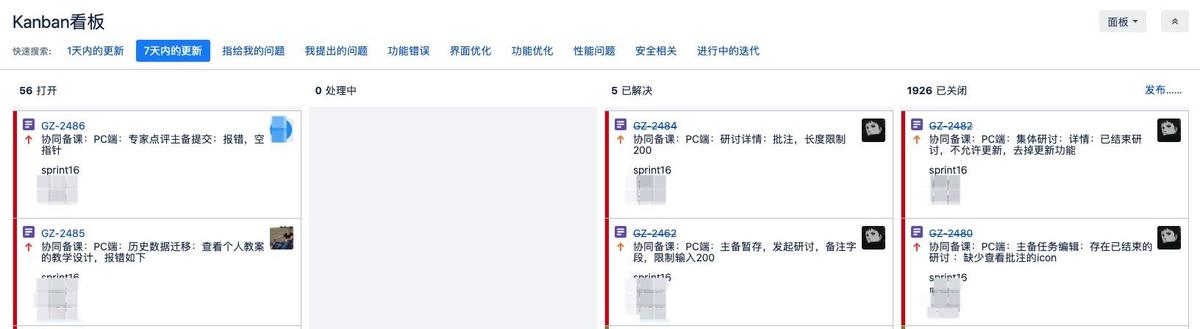
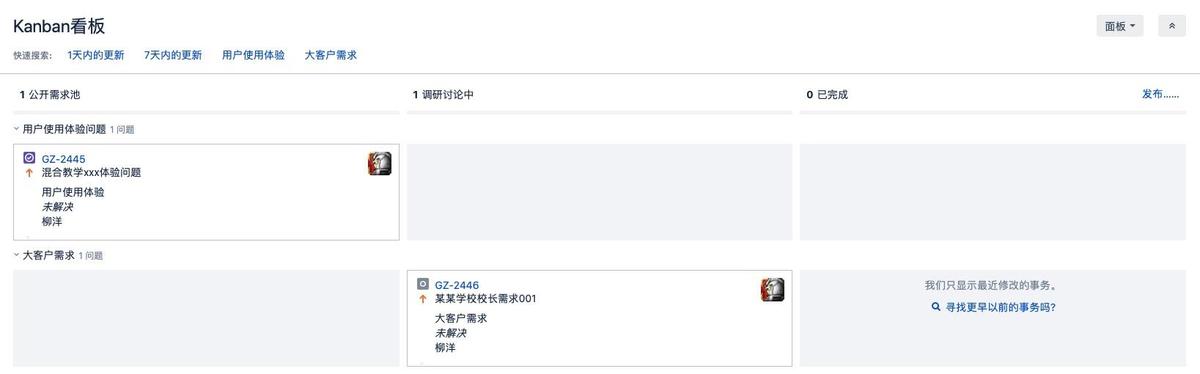
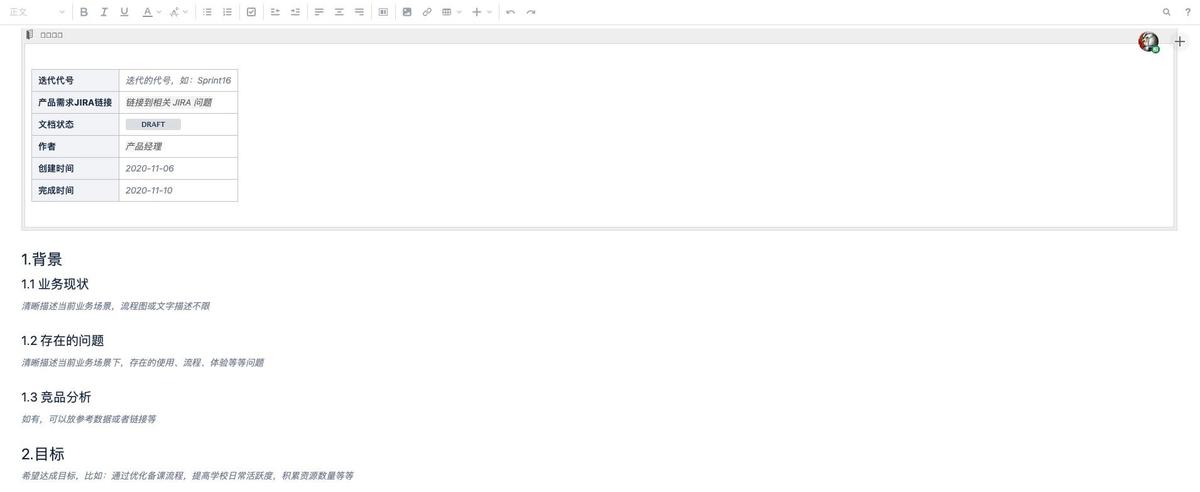
为什么需要
- 降低Review成本,可以明确知道本次提交的改变和影响
- 规范整个Team的提交习惯,对技术素养的养成有益
- 可以通过统一工具,抽取规范的message自动形成change log
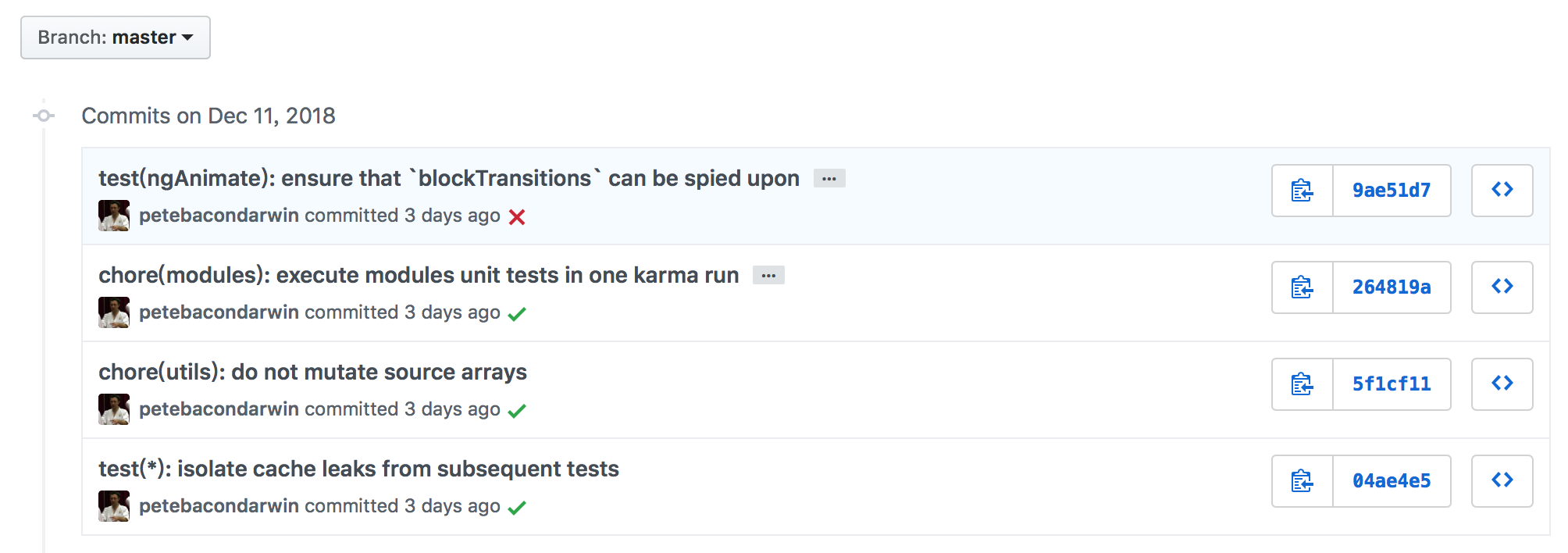
GitHub Angular Demo
目前Github的Angular项目,就是完全采用规范的Git Message来进行日常的提交管理和发布管理的,下面是这个项目的Commit记录,和自动根据commit生成的change log
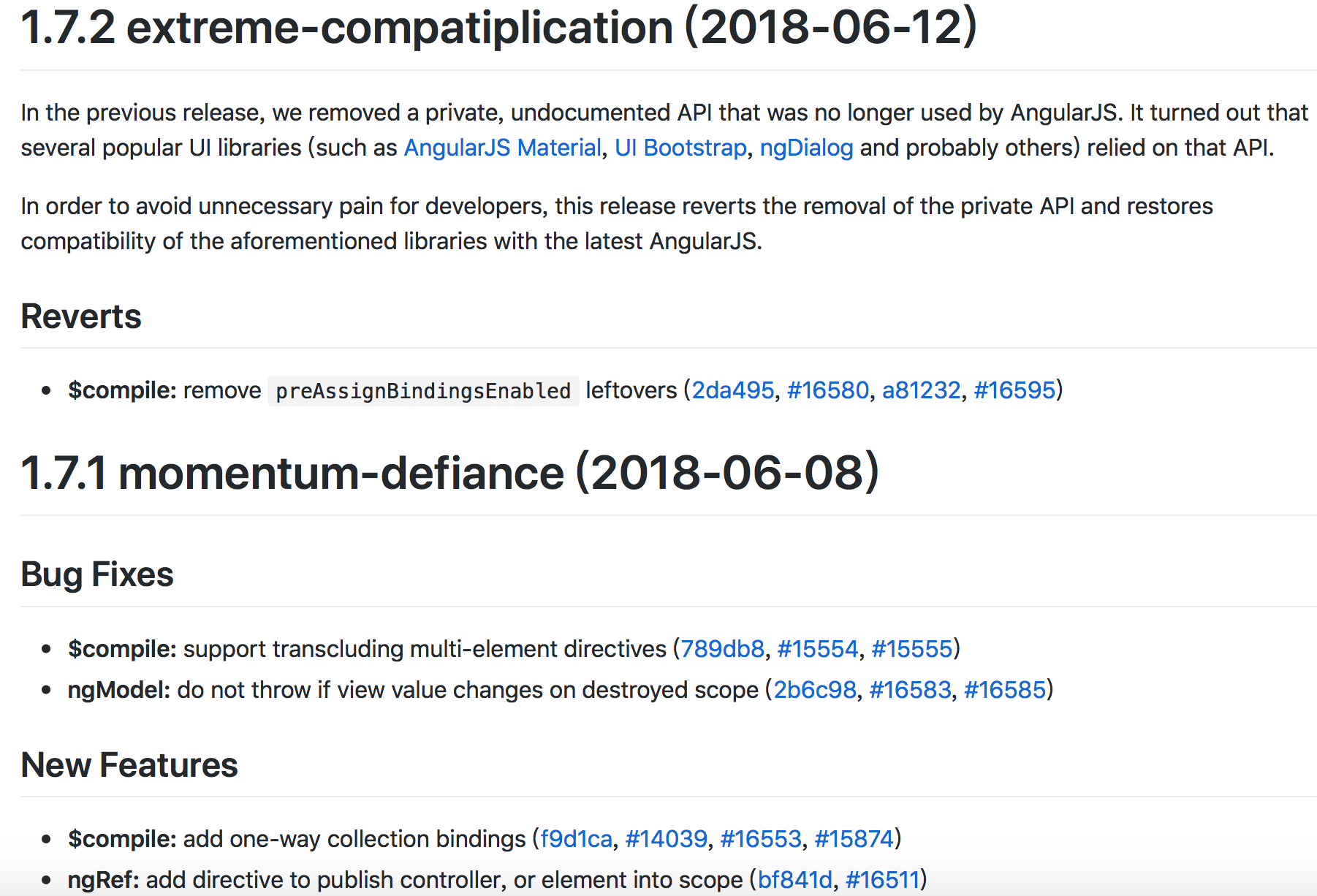
遵循什么规范
目前,使用较多的是AngularJS规范
1 | # 包括三个部分:Header,Body 和 Footer |
Header
包括三个字段:type(必需)、scope(可选)和subject(必需)
任何一行都不能超过100个字符
type
用于说明 commit 的类别,类型包含如下几种
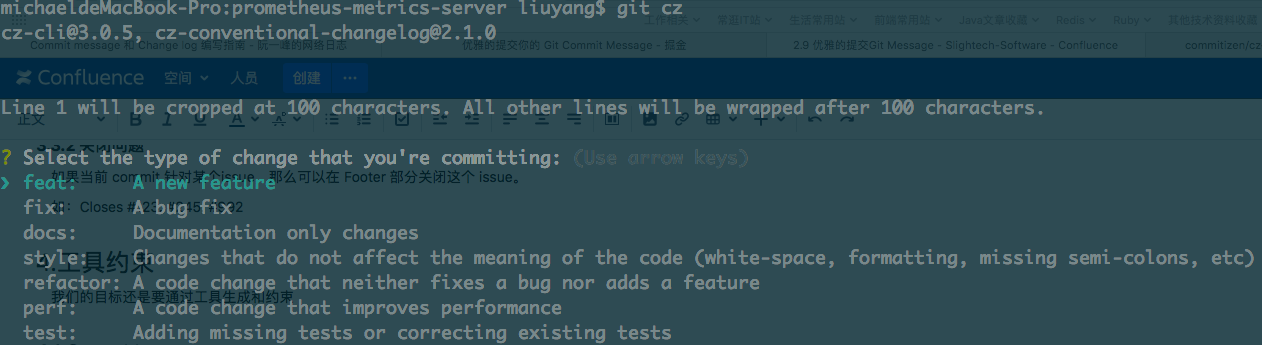
- feat: A new feature
- fix: A bug fix
- docs: Documentation only changes
- style: Changes that do not affect the meaning of the code (white-space, formatting, missing semi-colons, etc)
- refactor: A code change that neither fixes a bug nor adds a feature
- perf: A code change that improves performance
- test: Adding missing or correcting existing tests
- chore: Changes to the build process or auxiliary tools and libraries such as documentation generation
- revert: Reverts a previous commit
- build: Changes that affect the build system or external dependencies (example scopes: gulp, broccoli, npm)
- ci: Changes to our CI configuration files and scripts (example scopes: Travis, Circle, BrowserStack, SauceLabs)
如果type为feat和fix,则该 commit 将肯定出现在 Change log 之中。其他情况由你决定,要不要放入 Change log。
scope
用于说明 commit 影响的范围,比如数据层、控制层、视图层等等,视项目不同而不同
subject
subject是 commit 目的的简短描述
Body
Body 部分是对本次 commit 的详细描述,可以分成多行
Footer
Footer 部分只用于两种情况
不兼容变动
如果当前代码与上一个版本不兼容,则 Footer 部分以BREAKING CHANGE开头,后面是对变动的描述、以及变动理由和迁移方法
关闭问题
如果当前 commit 针对某个issue,那么可以在 Footer 部分关闭这个 issue。
如:Closes #123, #245, #992
工具约束
我们的目标还是要通过工具生成和约束
Commitizen
commitizen/cz-cli 代替git commit
我们需要借助它提供的 git cz 命令替代我们的 git commit 命令, 帮助我们生成符合规范的 commit message
1 | # 如何安装,在安装之前请先安装npm |
除此之外, 我们还需要为 commitizen 指定一个 Adapter 比如: cz-conventional-changelog (一个符合 Angular团队规范的 preset). 使得 commitizen 按照我们指定的规范帮助我们生成 commit message
1 | # 进入到我们项目的根目录 |
现在我们就可以用git cz去进行提交了
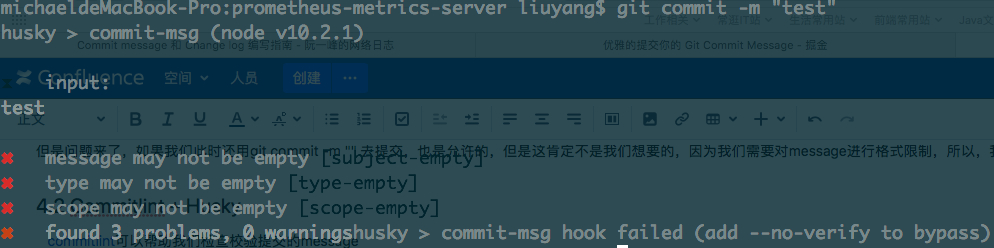
但是问题来了,如果我们此时还用git commit -m “” 去提交,也是允许的,但是这肯定不是我们想要的,因为我们需要对message进行格式限制,所以,我们需要下面的检验插件commitlint + Husky
Commitlint + Husky
commitlint可以帮助我们检查校验提交的message
如果我们提交的不符合指向的规范, 直接拒绝提交
校验 commit message 的最佳方式是结合 git hook, 所以需要配合Husky
1 | # 在我们的项目根目录 |
现在,我们可以在试试git commit -m “test”看看是否可以正常提交,应该会得到下面的拦截记录
Standard Version
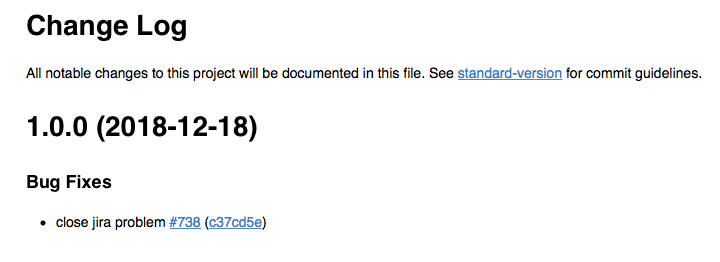
通过以上工具的帮助, 我们的工程 commit message 应该是符合Angular团队那套,这样也便于我们借助standard-version这样的工具, 自动生成 CHANGELOG, 甚至是语义化的版本号(Semantic Version)
1 | # 在项目根目录 |
会在我们项目根目录生成一个CHANGELOG.md文件,如下所示
项目中如何使用
如果我们已经完成了上述操作,会发现我们最终会得到一个package.json,我们只需要把package.json / commitlint.config.js提交版本库即可
把node_modules 和 package-lock.json都加入git忽略文件
下次再新clone项目后,直接在项目根目录运行npm install即可完成上述所有步骤
PS:NPM有时候国外镜像不稳定,可以切换淘宝镜像
1 | npm config set registry https://registry.npm.taobao.org |