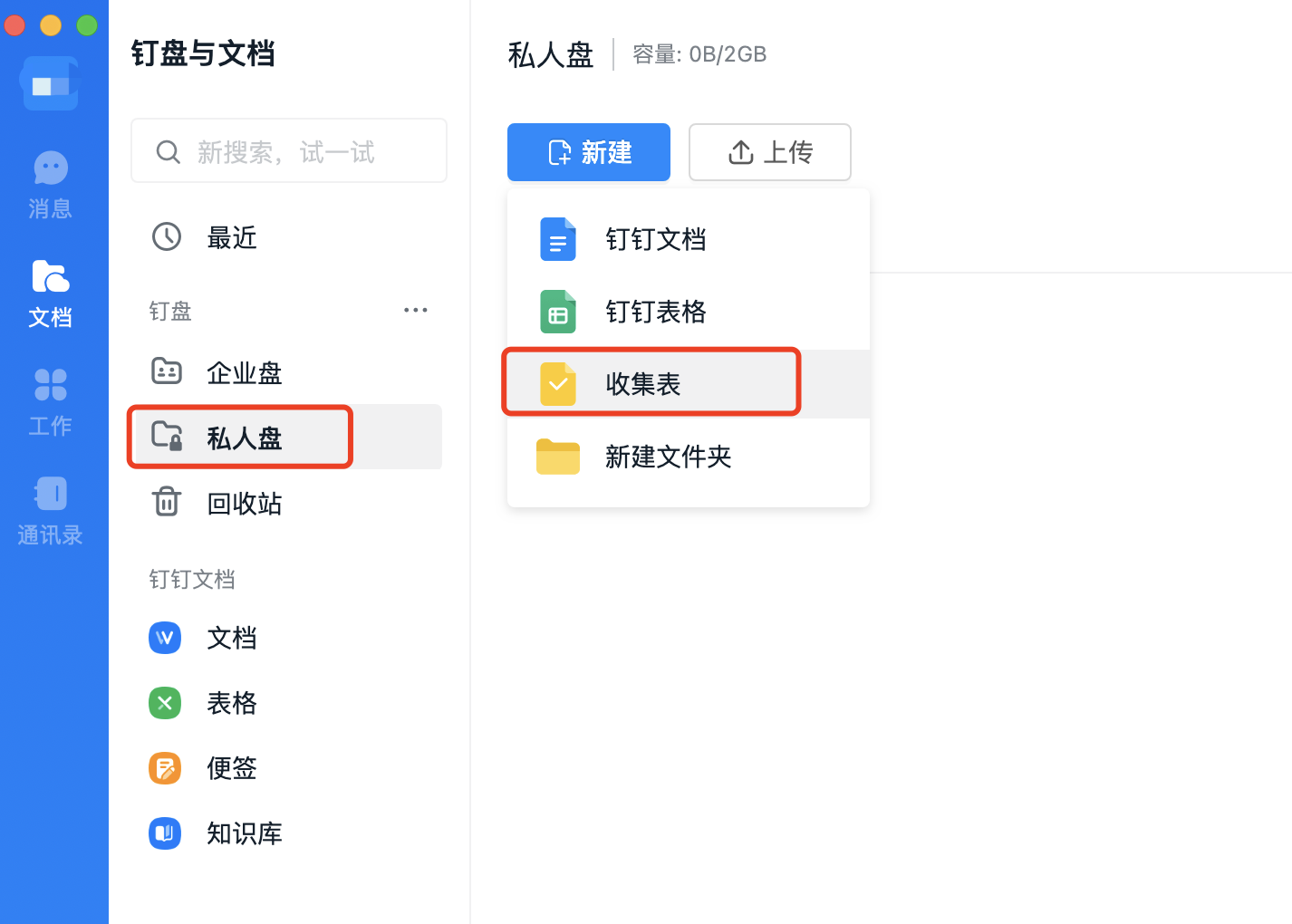
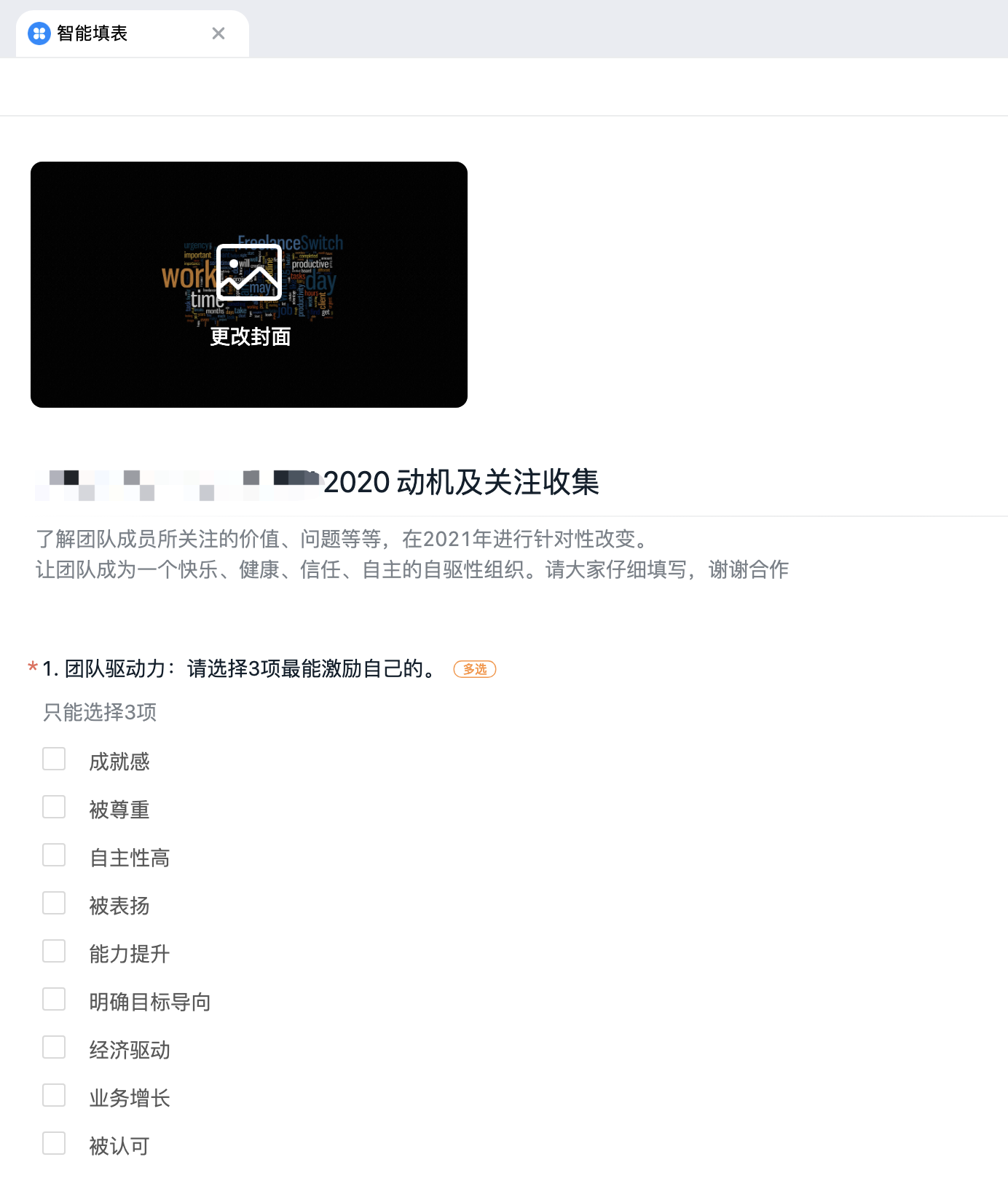
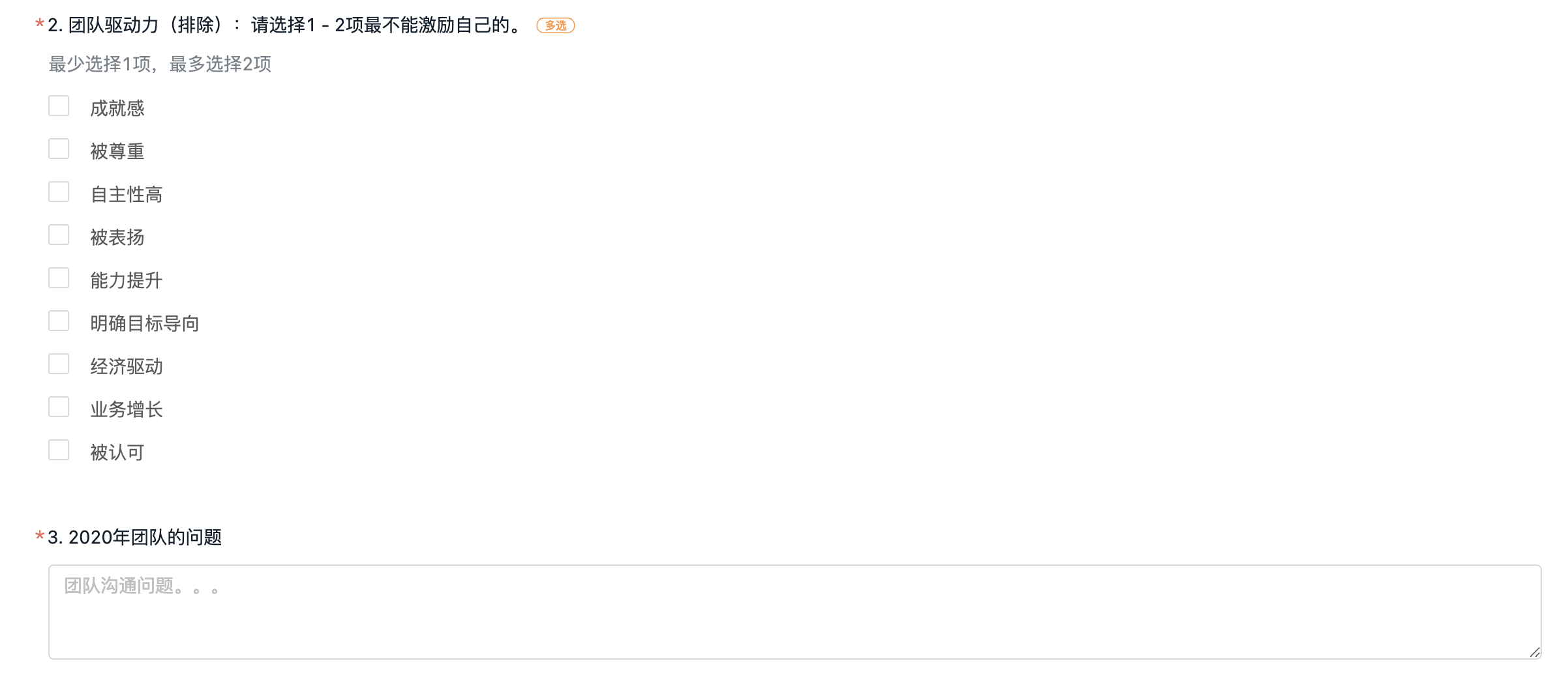
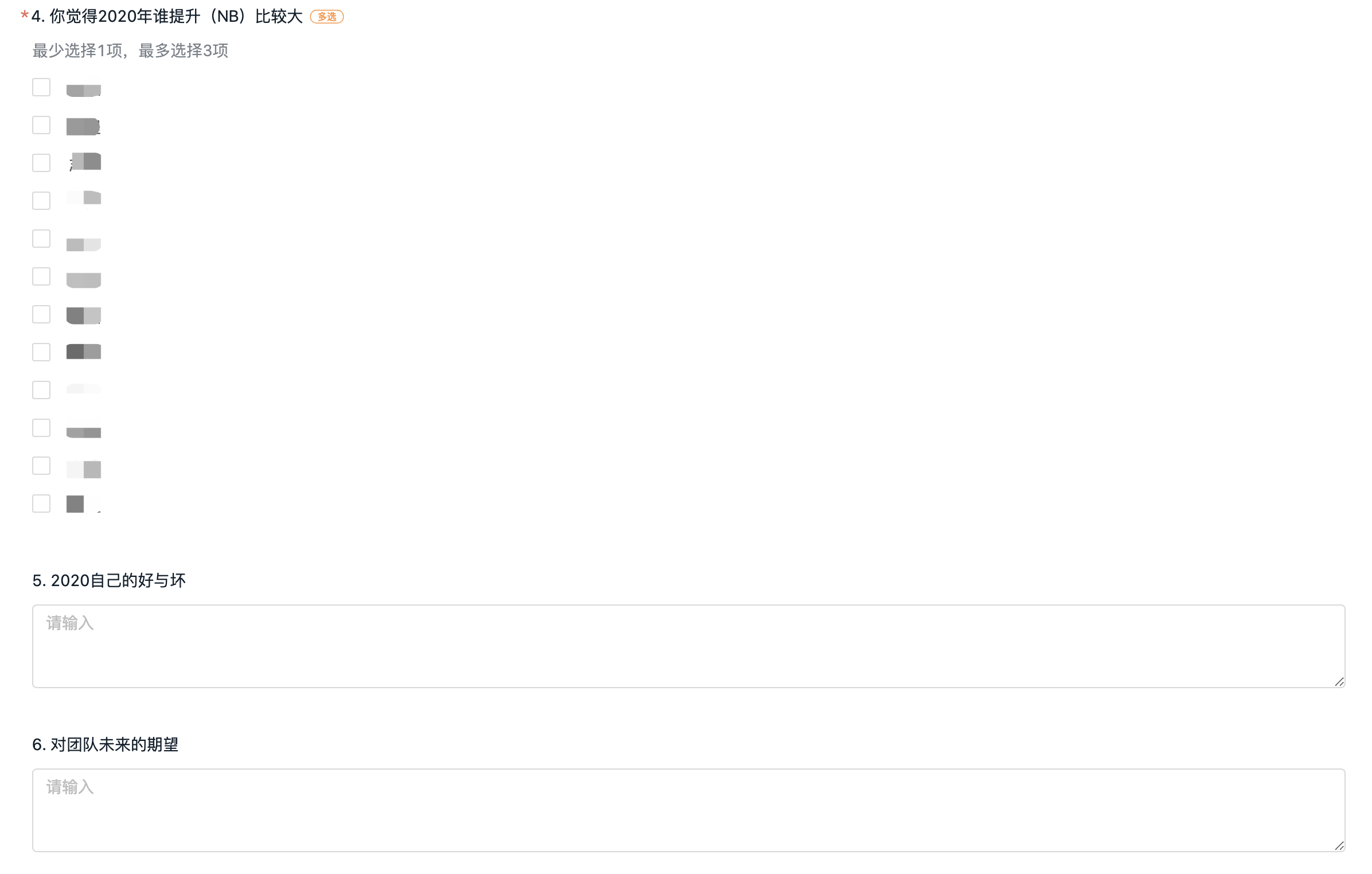
为什么要总结
行有不得,反求诸己。 —— 出自《孟子》
学会从自身寻找原因,可以帮助我们成为更好的人。
其实,无论是个人还是团队,在年底进行一些有针对性的总结(建议是数据化呈现),对于找到自身问题,提高和改进,还是有挺大帮助的。
切忌,不是为了总结而总结。应该学会从客观的事实(数据化是个不错的手段),寻找问题的发生原因,从而尝试做改变,去改善问题。
准备工作
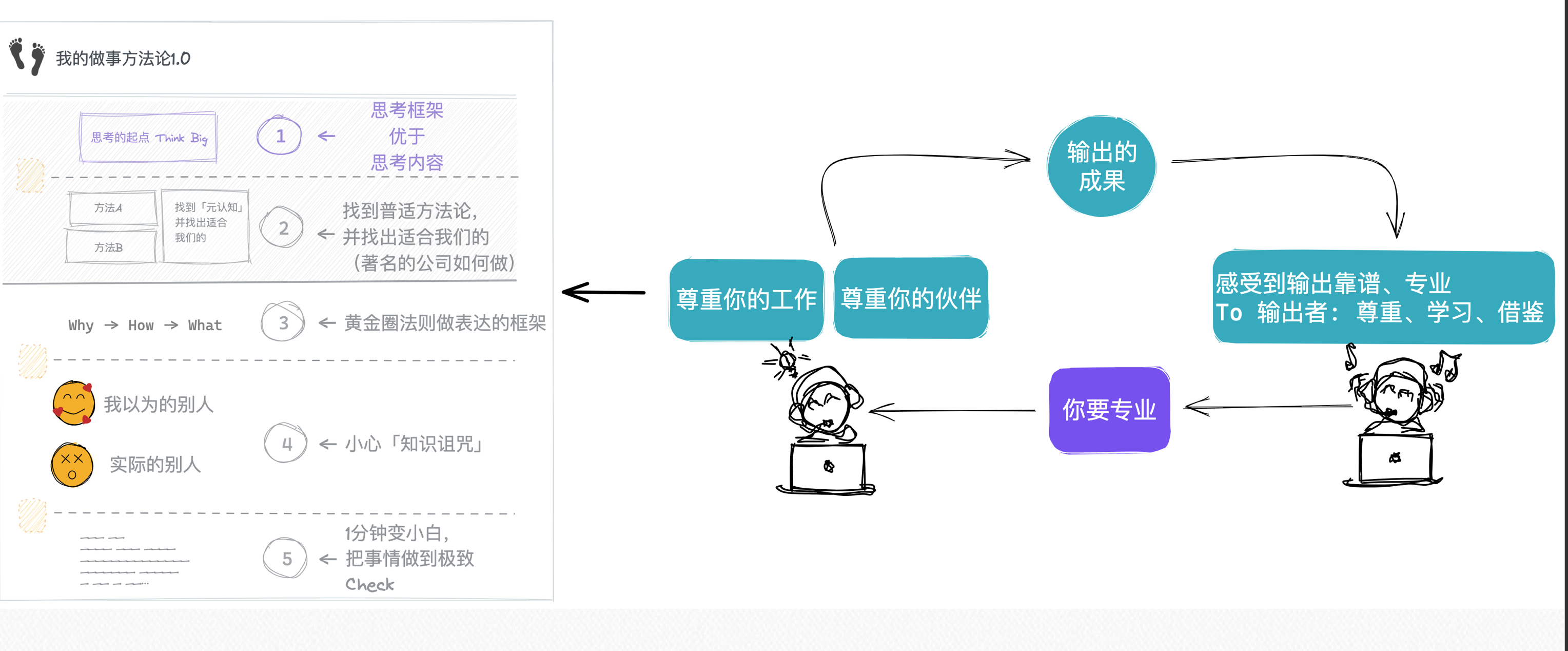
💡 思考的框架 优于 思考的内容
避免流水账
作为研发Leader,在做总结时,我会首先避免流水账,不要先思考这1年来,我们做了什么,这样很容易陷入到细节中。
思考:我们需要什么样子的团队
小时候,经常被问到,你想成为什么样的人。其实,管理团队也是一样的逻辑,先思考「我们需要什么样的团队」。在2021年初,我们团队定下的指导思想是「成为专业的团队」,所以,在接下来的1年时间里,我们都在遵循这个指导思想。
建设团队的指导思想
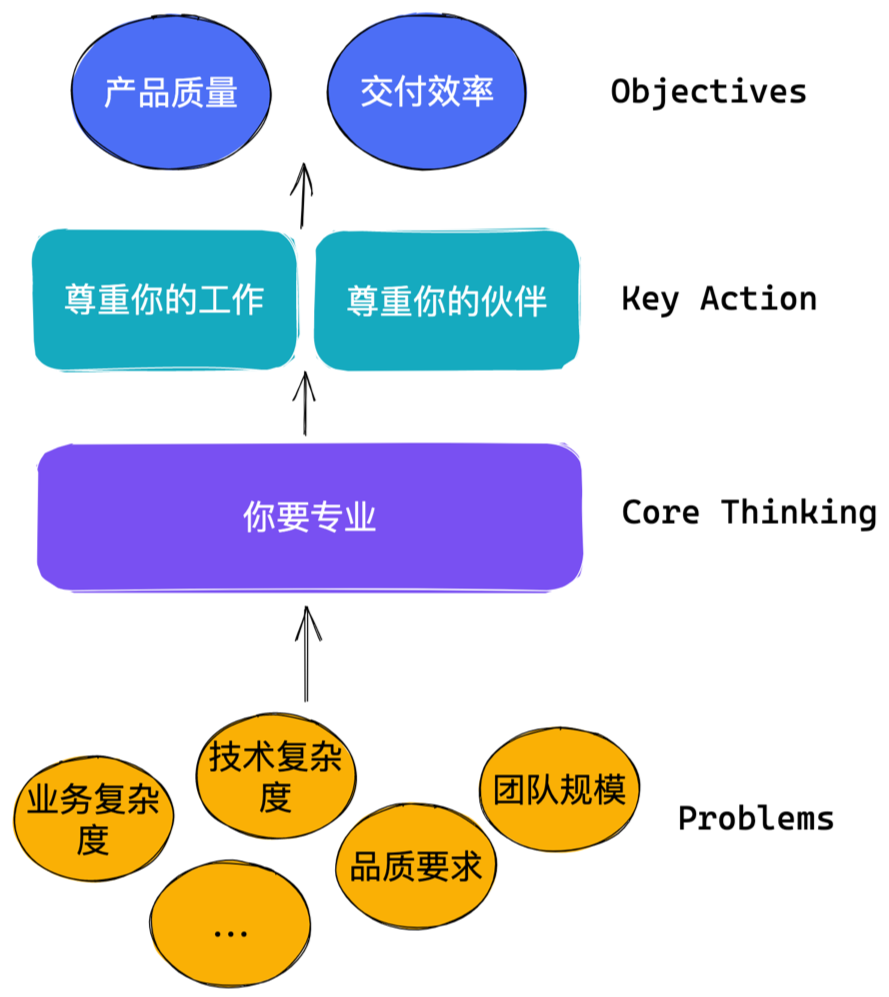
抽象团队的工作分类

我的思路
做了什么
建议按照工作分类进行重点事项的陈述
做到了什么,没做到什么
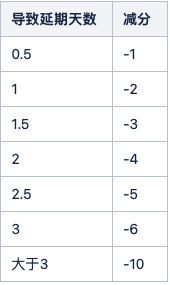
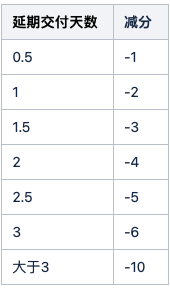
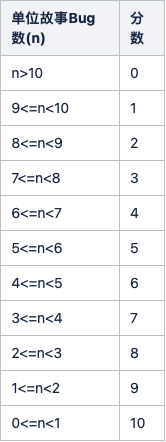
从做的事情,客观的数据反馈,和年初的目标,进行综合对比,进行分析,找到问题原因,为来年提供改善思路
分享自己或团队其他人的做事心得(方法)
意在提高团队认知,授人以鱼不如授人以渔
我的2021总结(部分)
做了什么
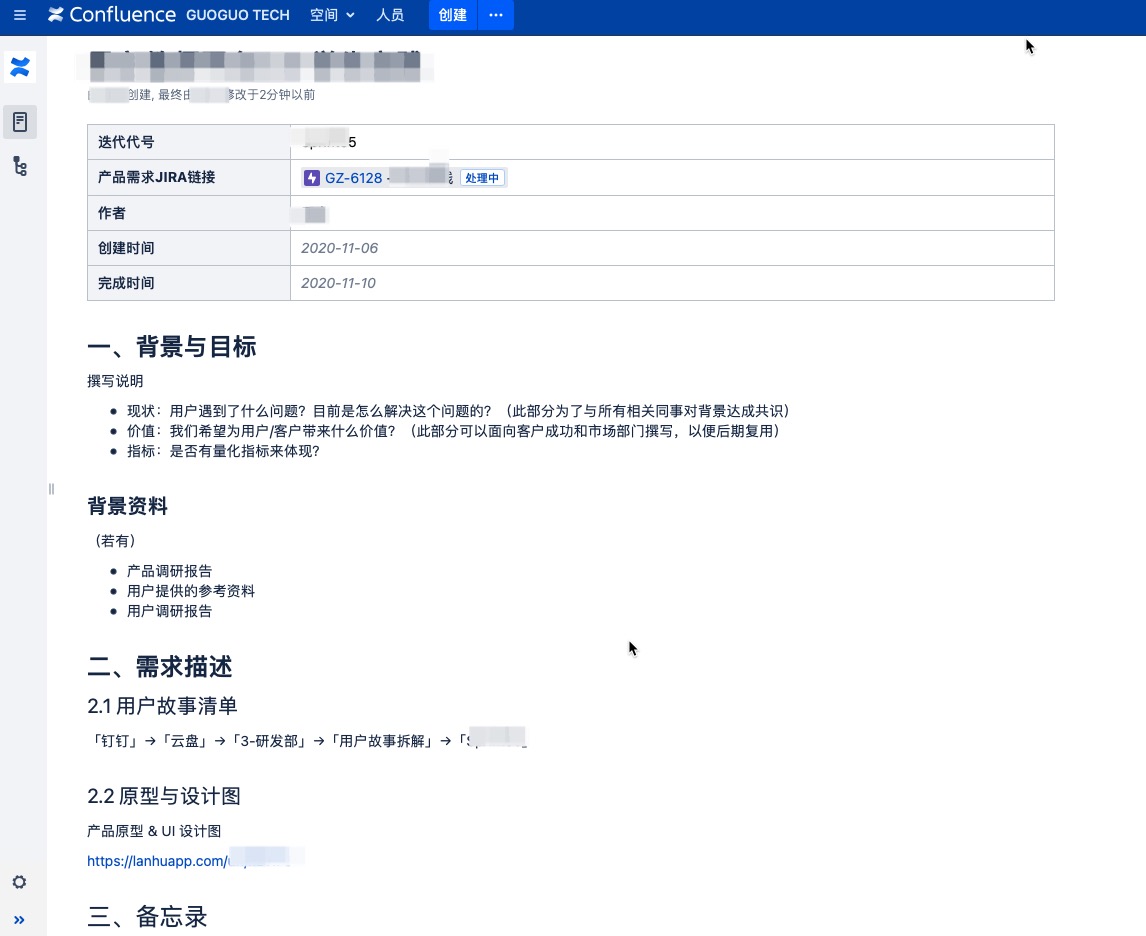
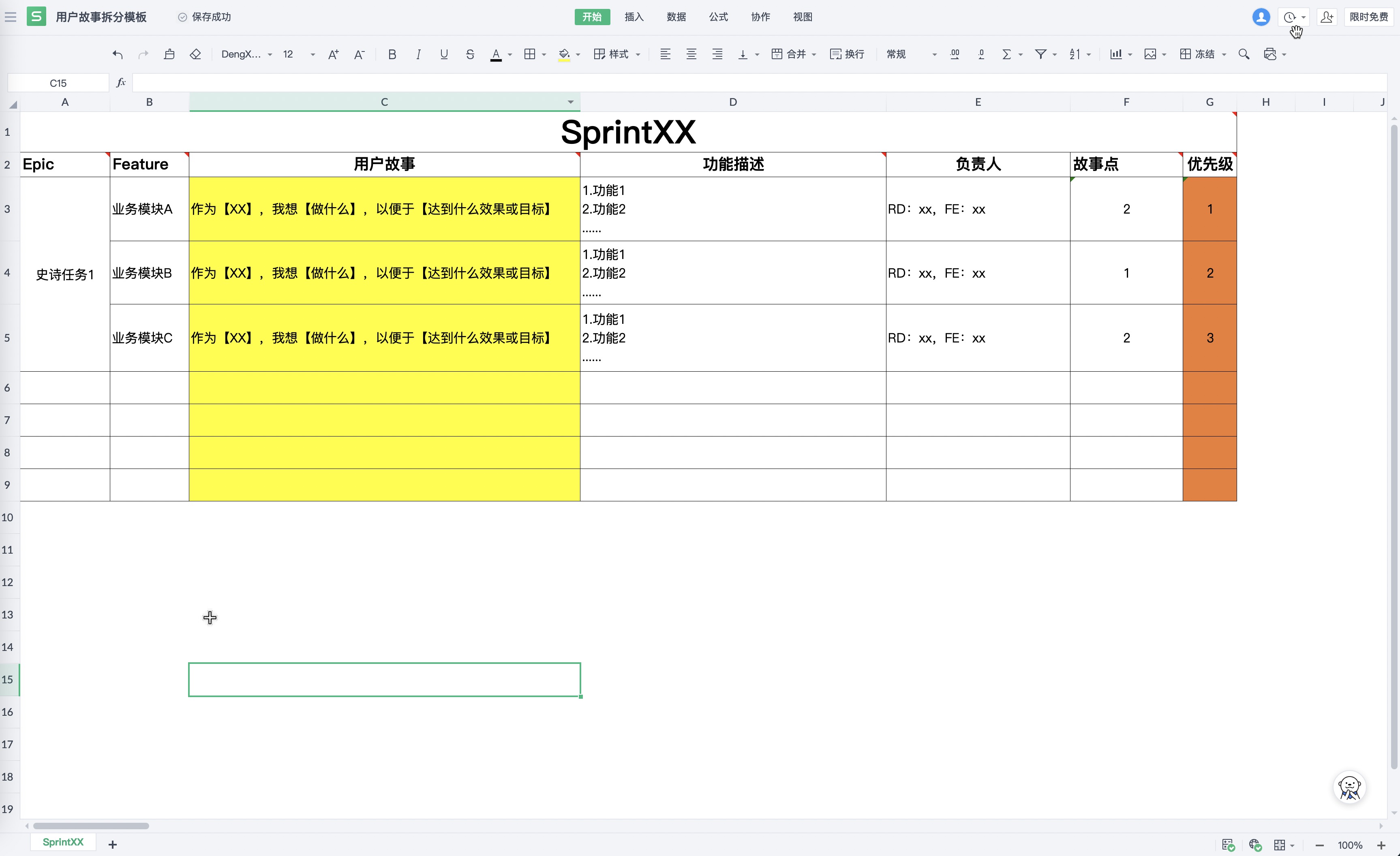
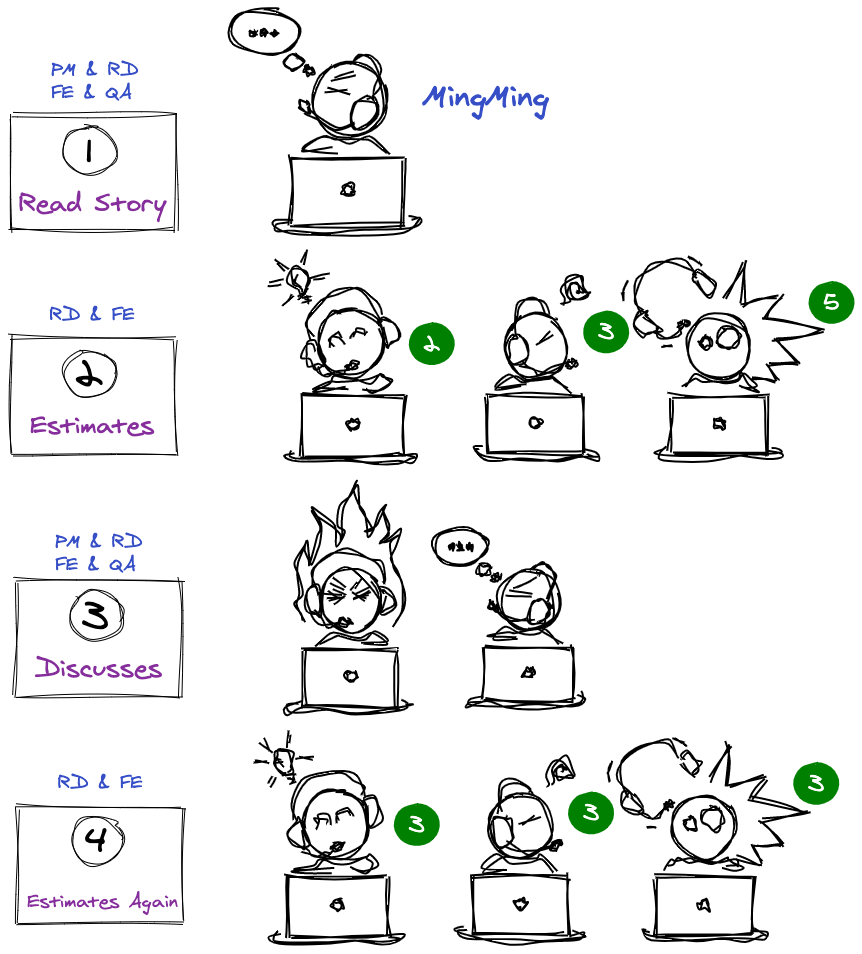
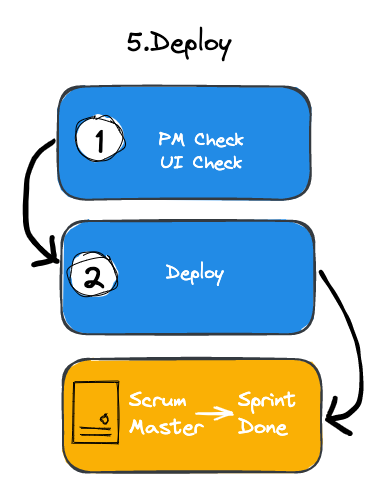
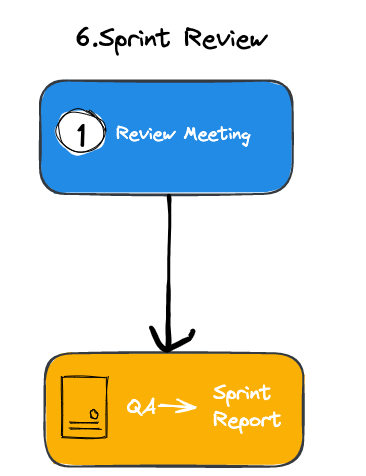
Iteration 迭代

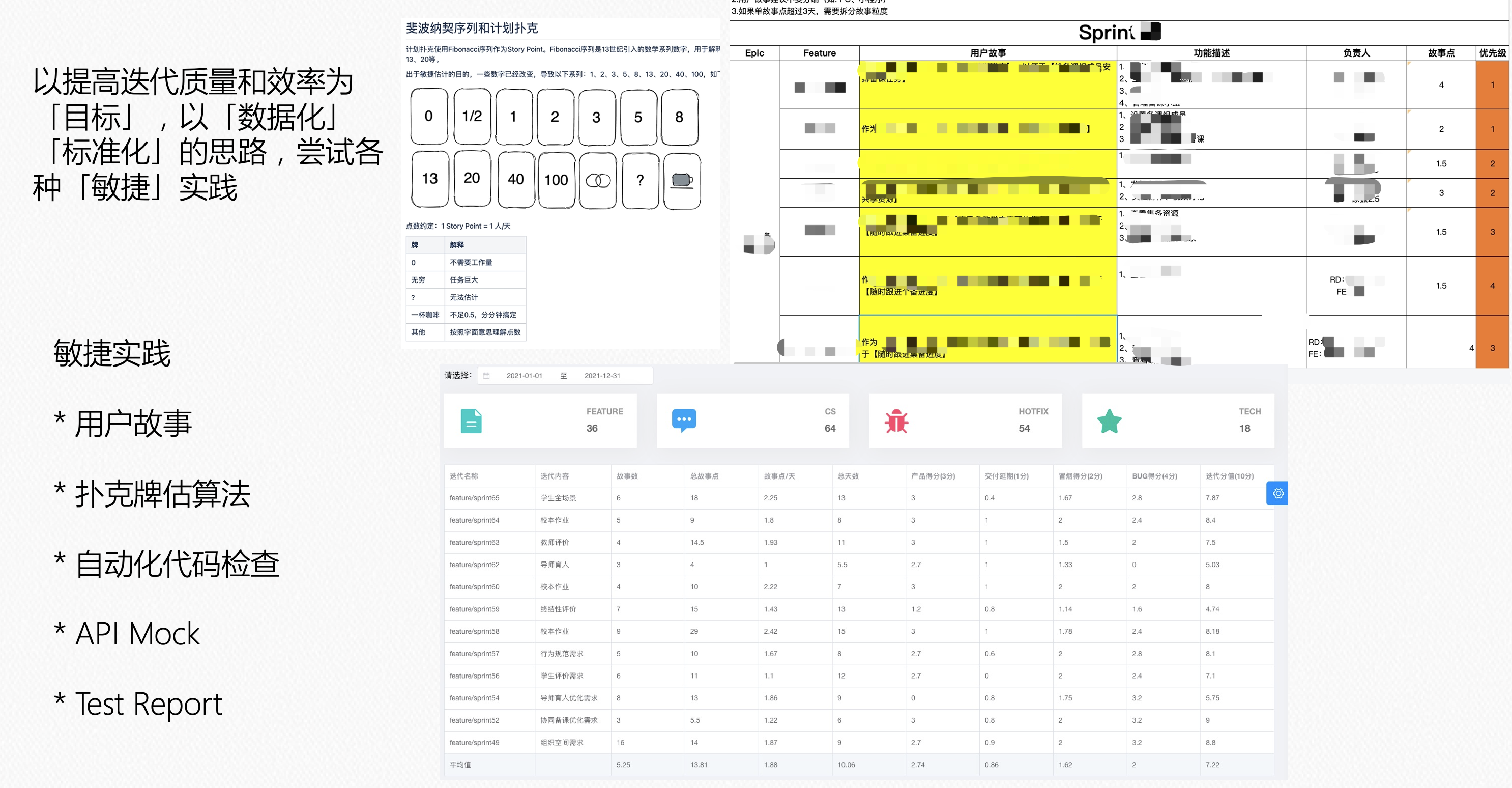
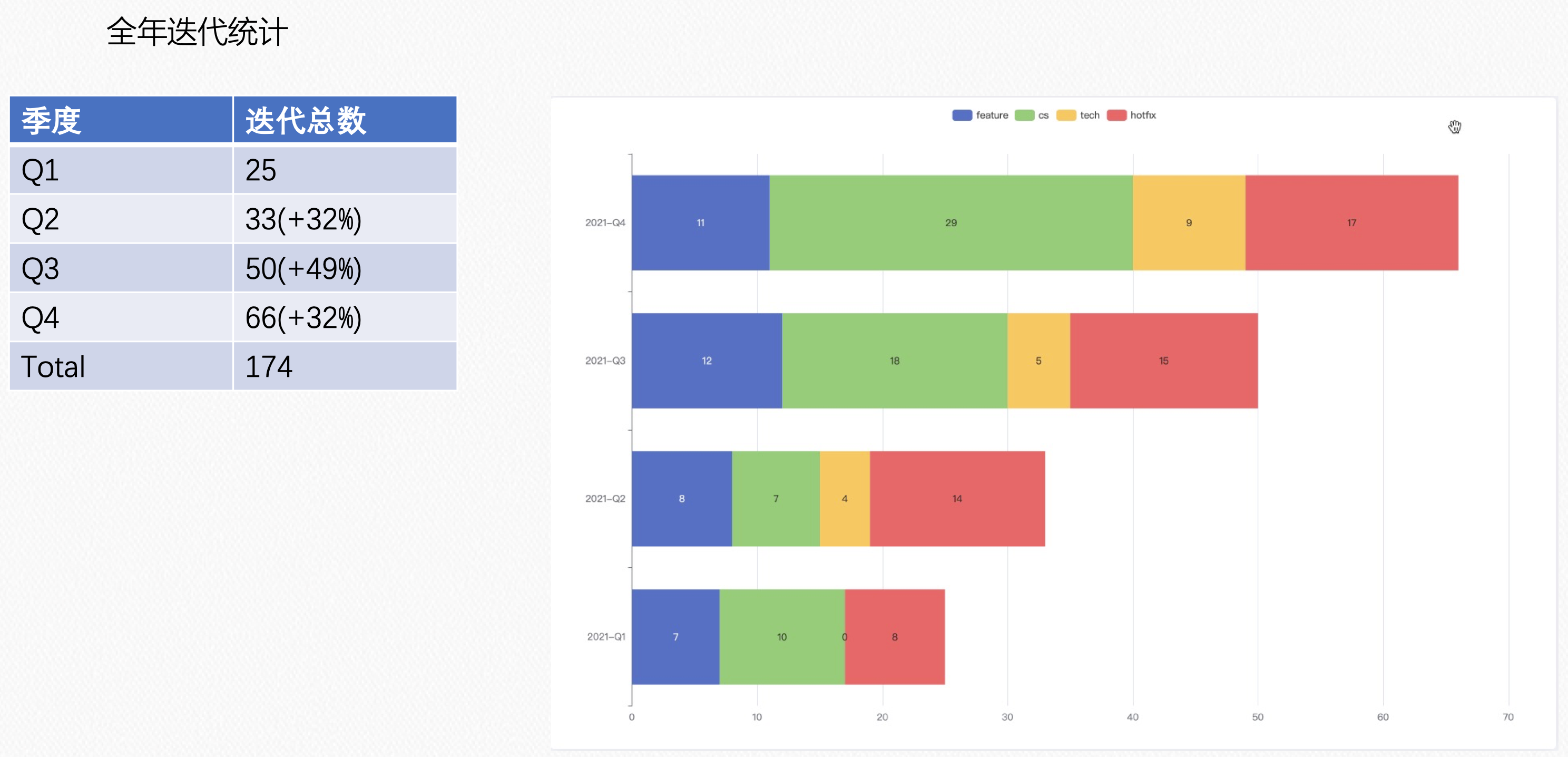
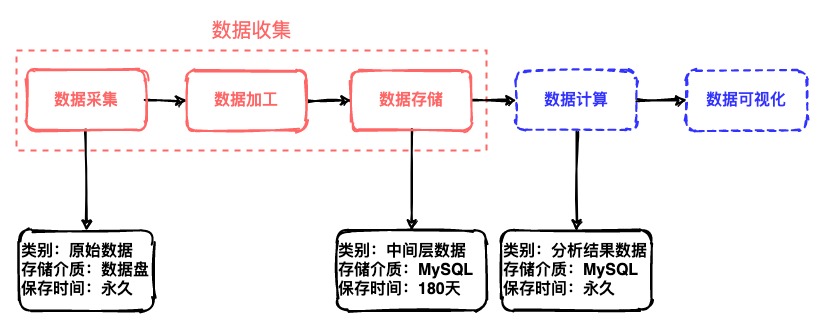
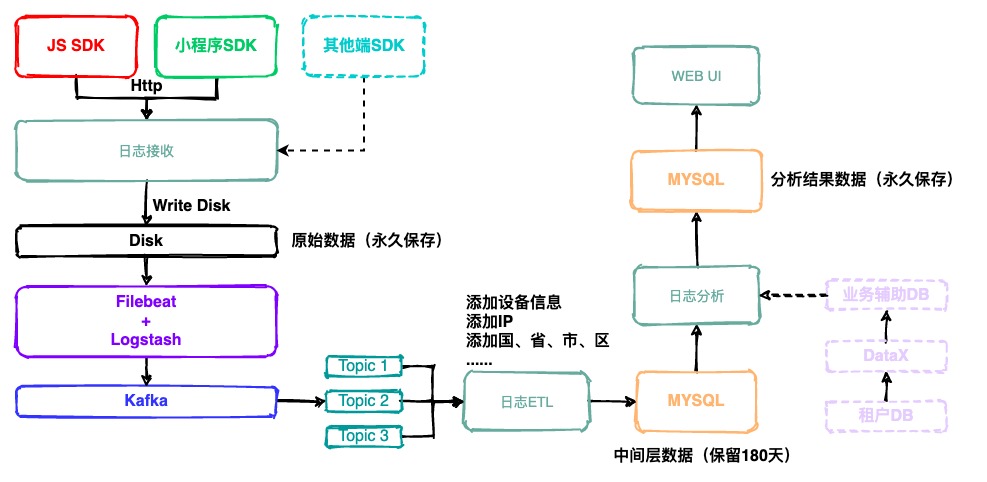
Arch 架构
- Backend
- 涉及内容较敏感
- Frontend
- 涉及内容较敏感
- Backend
Assets 技术资产
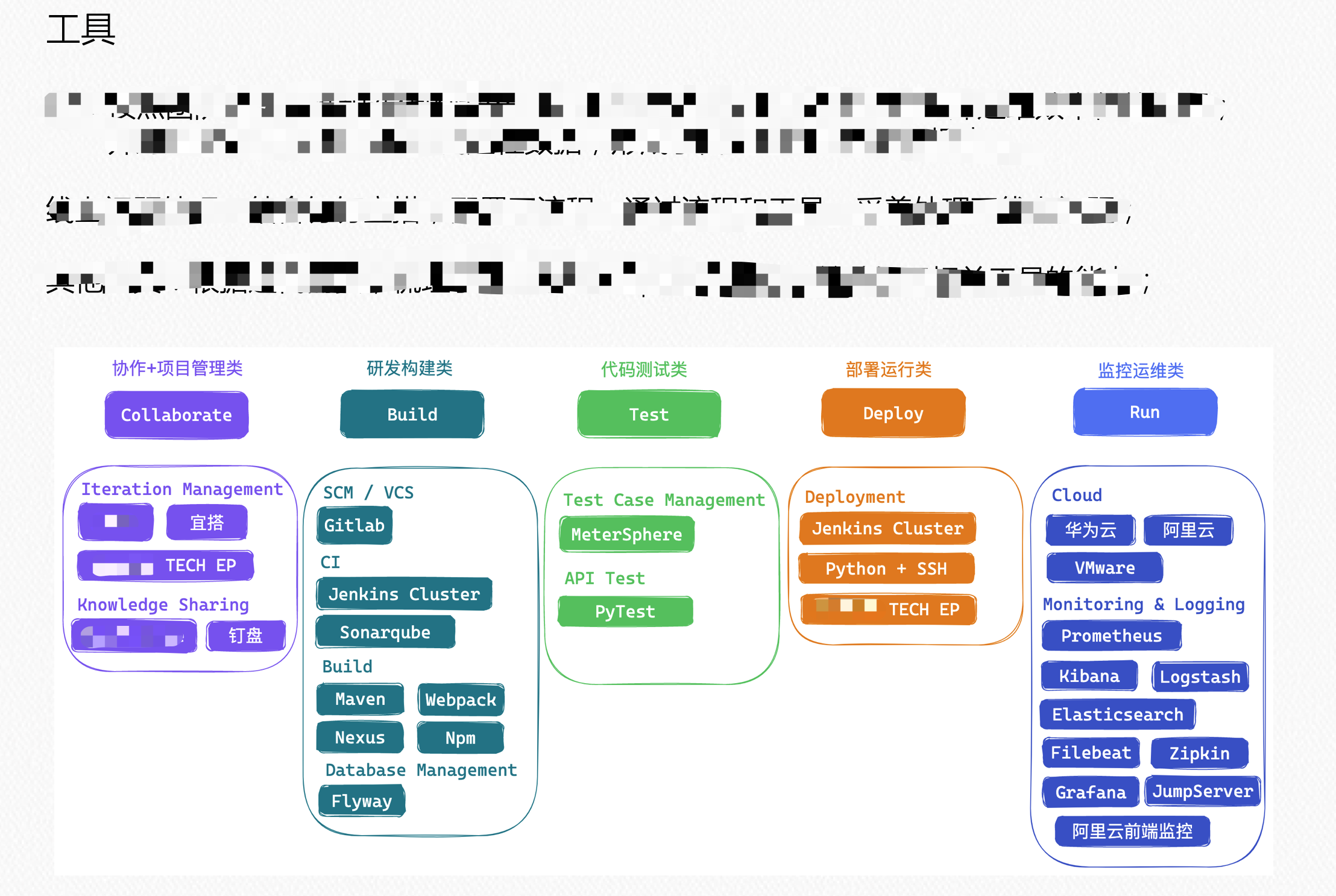
- 工具
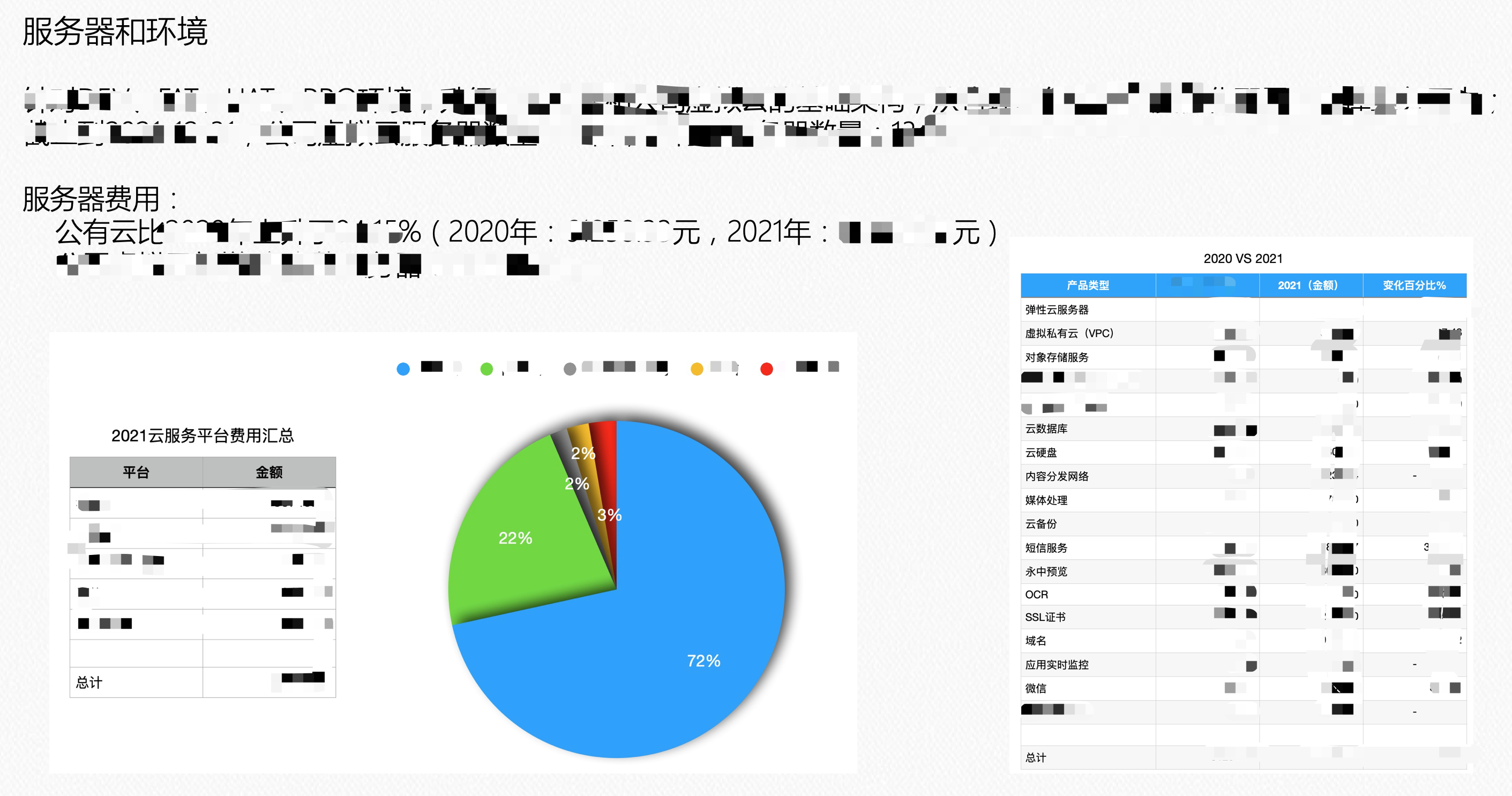
- 服务器和环境
- 代码规划&设计
- 涉及内容较敏感
- 工具
团队
- 架构
- 涉及内容较敏感
- 激励
- 涉及内容较敏感
- 活动
- 涉及内容较敏感
- 架构
做到了什么,没做到什么
- 涉及内容较敏感
分享自己或团队其他人的做事心得(方法)